Exam - Mon 24, Aug 2020
Scientific Programming - Data Science @ University of Trento
Download exercises and solutions
Introduction
Taking part to this exam erases any vote you had before
What to do
Download
sciprog-ds-2020-08-24-exam.zipand extract it on your desktop. Folder content should be like this:Rename
sciprog-ds-2020-08-24-FIRSTNAME-LASTNAME-IDfolder: put your name, lastname an id number, likesciprog-ds-2020-08-24-john-doe-432432
From now on, you will be editing the files in that folder. At the end of the exam, that is what will be evaluated.
Edit the files following the instructions in this worksheet for each exercise. Every exercise should take max 25 mins. If it takes longer, leave it and try another exercise.
When done:
if you have unitn login: zip and send to examina.icts.unitn.it/studente
If you don’t have unitn login: tell instructors and we will download your work manually
Part A - Prezzario
NOTICE: this part of the exam was ported to softpython website
There you can find a more curated version (notice it may be longer than here)
Open Jupyter and start editing this notebook exam-2020-08-24.ipynb
You are going to analyze the dataset EPPAT-2018-new-compact.csv, which is the price list for all products and services the Autonomous Province of Trento may require. Source: dati.trentino.it
DO NOT WASTE TIME LOOKING AT THE WHOLE DATASET!
The dataset is quite complex, please focus on the few examples we provide
We will show examples with pandas, but it is not required to solve the exercises.
[1]:
import pandas as pd
import numpy as np
pd.set_option('display.max_colwidth', -1)
df = pd.read_csv('EPPAT-2018-new-compact.csv', encoding='latin-1')
The dataset contains several columns, but we will consider the following ones:
[2]:
df = df[['Codice Prodotto', 'Descrizione Breve Prodotto', 'Categoria', 'Prezzo']]
df[:22]
[2]:
| Codice Prodotto | Descrizione Breve Prodotto | Categoria | Prezzo | |
|---|---|---|---|---|
| 0 | A.02.35.0050 | ATTREZZATURA PER INFISSIONE PALI PILOTI | NaN | NaN |
| 1 | A.02.35.0050.010 | Attrezzatura per infissione pali piloti. | Noli e trasporti | 109.09 |
| 2 | A.02.40 | ATTREZZATURE SPECIALI | NaN | NaN |
| 3 | A.02.40.0010 | POMPA COMPLETA DI MOTORE | NaN | NaN |
| 4 | A.02.40.0010.010 | fino a mm 50. | Noli e trasporti | 2.21 |
| 5 | A.02.40.0010.020 | oltre mm 50 fino a mm 100. | Noli e trasporti | 3.36 |
| 6 | A.02.40.0010.030 | oltre mm 100 fino a mm 150. | Noli e trasporti | 4.42 |
| 7 | A.02.40.0010.040 | oltre mm 150 fino a mm 200. | Noli e trasporti | 5.63 |
| 8 | A.02.40.0010.050 | oltre mm 200. | Noli e trasporti | 6.84 |
| 9 | A.02.40.0020 | GRUPPO ELETTROGENO | NaN | NaN |
| 10 | A.02.40.0020.010 | fino a 10 KW | Noli e trasporti | 8.77 |
| 11 | A.02.40.0020.020 | oltre 10 fino a 13 KW | Noli e trasporti | 9.94 |
| 12 | A.02.40.0020.030 | oltre 13 fino a 20 KW | Noli e trasporti | 14.66 |
| 13 | A.02.40.0020.040 | oltre 20 fino a 28 KW | Noli e trasporti | 15.62 |
| 14 | A.02.40.0020.050 | oltre 28 fino a 36 KW | Noli e trasporti | 16.40 |
| 15 | A.02.40.0020.060 | oltre 36 fino a 56 KW | Noli e trasporti | 28.53 |
| 16 | A.02.40.0020.070 | oltre 56 fino a 80 KW | Noli e trasporti | 44.06 |
| 17 | A.02.40.0020.080 | oltre 80 fino a 100 KW | Noli e trasporti | 50.86 |
| 18 | A.02.40.0020.090 | oltre 100 fino a 120 KW | Noli e trasporti | 55.88 |
| 19 | A.02.40.0020.100 | oltre 120 fino a 156 KW | Noli e trasporti | 80.47 |
| 20 | A.02.40.0020.110 | oltre 156 fino a 184 KW | Noli e trasporti | 94.00 |
| 21 | A.02.40.0030 | NASTRO TRASPORTATORE CON MOTORE AD ARIA COMPRESSA | NaN | NaN |
Pompa completa a motore Example
If we look at the dataset, in some cases we can spot a pattern like the following (rows 3 to 8 included):
[3]:
df[3:12]
[3]:
| Codice Prodotto | Descrizione Breve Prodotto | Categoria | Prezzo | |
|---|---|---|---|---|
| 3 | A.02.40.0010 | POMPA COMPLETA DI MOTORE | NaN | NaN |
| 4 | A.02.40.0010.010 | fino a mm 50. | Noli e trasporti | 2.21 |
| 5 | A.02.40.0010.020 | oltre mm 50 fino a mm 100. | Noli e trasporti | 3.36 |
| 6 | A.02.40.0010.030 | oltre mm 100 fino a mm 150. | Noli e trasporti | 4.42 |
| 7 | A.02.40.0010.040 | oltre mm 150 fino a mm 200. | Noli e trasporti | 5.63 |
| 8 | A.02.40.0010.050 | oltre mm 200. | Noli e trasporti | 6.84 |
| 9 | A.02.40.0020 | GRUPPO ELETTROGENO | NaN | NaN |
| 10 | A.02.40.0020.010 | fino a 10 KW | Noli e trasporti | 8.77 |
| 11 | A.02.40.0020.020 | oltre 10 fino a 13 KW | Noli e trasporti | 9.94 |
We see the first column holds product codes. If two rows share a code prefix, they belong to the same product type. As an example, we can take product A.02.40.0010, which has 'POMPA COMPLETA A MOTORE' as description (‘Descrizione Breve Prodotto’ column). The first row is basically telling us the product type, while the following rows are specifying several products of the same type (notice they all share the A.02.40.0010 prefix code until 'GRUPPO ELETTROGENO' excluded). Each
description specifies a range of values for that product: fino a means until to , and oltre means beyond.
Notice that:
first row has only one number
intermediate rows have two numbers
last row of the product series (row 8) has only one number and contains the word oltre ( beyond ) (in some other cases, last row of product series may have two numbers)
A1 extract_bounds
Write a function that given a Descrizione Breve Prodotto as a single string extracts the range contained within as a tuple.
If the string contains only one number n:
if it contains
UNTIL( ‘fino’ ) it is considered a first row with bounds(0,n)if it contains
BEYOND( ‘oltre’ ) it is considered a last row with bounds(n, math.inf)
DO NOT use constants like measure units ‘mm’, ‘KW’, etc in the code
Show solution[4]:
import math
#use this list to rmeove unneeded stuff
PUNCTUATION=[',','-','.','%']
UNTIL = 'fino'
BEYOND = 'oltre'
def extract_bounds(text):
raise Exception('TODO IMPLEMENT ME !')
assert extract_bounds('fino a mm 50.') == (0,50)
assert extract_bounds('oltre mm 50 fino a mm 100.') == (50,100)
assert extract_bounds('oltre mm 200.') == (200, math.inf)
assert extract_bounds('da diametro 63 mm a diametro 127 mm') == (63, 127)
assert extract_bounds('fino a 10 KW') == (0,10)
assert extract_bounds('oltre 156 fino a 184 KW') == (156,184)
assert extract_bounds('fino a 170 A, avviamento elettrico') == (0,170)
assert extract_bounds('oltre 170 A fino a 250 A, avviamento elettrico') == (170, 250)
assert extract_bounds('oltre 300 A, avviamento elettrico') == (300, math.inf)
assert extract_bounds('tetti piani o con bassa pendenza - fino al 10%') == (0,10)
assert extract_bounds('tetti a media pendenza - oltre al 10% e fino al 45%') == (10,45)
assert extract_bounds('tetti ad alta pendenza - oltre al 45%') == (45, math.inf)
A2 extract_product
Write a function that given a filename, a code and a unit, parses the csv until it finds the corresponding code and RETURNS one dictionary with relevant information for that product
Prezzo ( price ) must be converted to float
implement the parsing with a
csv.DictReader, see exampleas encoding, use
latin-1
[5]:
# Suppose we want to get all info about A.02.40.0010 prefix:
df[3:12]
[5]:
| Codice Prodotto | Descrizione Breve Prodotto | Categoria | Prezzo | |
|---|---|---|---|---|
| 3 | A.02.40.0010 | POMPA COMPLETA DI MOTORE | NaN | NaN |
| 4 | A.02.40.0010.010 | fino a mm 50. | Noli e trasporti | 2.21 |
| 5 | A.02.40.0010.020 | oltre mm 50 fino a mm 100. | Noli e trasporti | 3.36 |
| 6 | A.02.40.0010.030 | oltre mm 100 fino a mm 150. | Noli e trasporti | 4.42 |
| 7 | A.02.40.0010.040 | oltre mm 150 fino a mm 200. | Noli e trasporti | 5.63 |
| 8 | A.02.40.0010.050 | oltre mm 200. | Noli e trasporti | 6.84 |
| 9 | A.02.40.0020 | GRUPPO ELETTROGENO | NaN | NaN |
| 10 | A.02.40.0020.010 | fino a 10 KW | Noli e trasporti | 8.77 |
| 11 | A.02.40.0020.020 | oltre 10 fino a 13 KW | Noli e trasporti | 9.94 |
A call to
pprint(extract_product('EPPAT-2018-new-compact.csv', 'A.02.40.0010', 'mm'))
Must produce:
{'category': 'Noli e trasporti',
'code': 'A.02.40.0010',
'description': 'POMPA COMPLETA DI MOTORE',
'measure_unit': 'mm',
'models': [{'bounds': (0, 50), 'price': 2.21, 'subcode': '010'},
{'bounds': (50, 100), 'price': 3.36, 'subcode': '020'},
{'bounds': (100, 150), 'price': 4.42, 'subcode': '030'},
{'bounds': (150, 200), 'price': 5.63, 'subcode': '040'},
{'bounds': (200, math.inf),'price': 6.84, 'subcode': '050'}]}
Notice that if we append subcode to code (with a dot) we obtain the full product code.
[6]:
import csv
from pprint import pprint
def extract_product(filename, code, measure_unit):
raise Exception('TODO IMPLEMENT ME !')
pprint(extract_product('EPPAT-2018-new-compact.csv', 'A.02.40.0010', 'mm'))
assert extract_product('EPPAT-2018-new-compact.csv', 'A.02.40.0010', 'mm') == \
{'category': 'Noli e trasporti',
'code': 'A.02.40.0010',
'description': 'POMPA COMPLETA DI MOTORE',
'measure_unit': 'mm',
'models': [{'bounds': (0, 50), 'price': 2.21, 'subcode': '010'},
{'bounds': (50, 100), 'price': 3.36, 'subcode': '020'},
{'bounds': (100, 150), 'price': 4.42, 'subcode': '030'},
{'bounds': (150, 200), 'price': 5.63, 'subcode': '040'},
{'bounds': (200, math.inf),'price': 6.84, 'subcode': '050'}]}
#pprint(extract_product('EPPAT-2018-new-compact.csv', 'A.02.40.0020', 'KW'))
#pprint(extract_product('EPPAT-2018-new-compact.csv', 'B.02.10.0042', 'mm'))
#pprint(extract_product('EPPAT-2018-new-compact.csv','B.30.10.0010', '%'))
{'category': 'Noli e trasporti',
'code': 'A.02.40.0010',
'description': 'POMPA COMPLETA DI MOTORE',
'measure_unit': 'mm',
'models': [{'bounds': (0, 50), 'price': 2.21, 'subcode': '010'},
{'bounds': (50, 100), 'price': 3.36, 'subcode': '020'},
{'bounds': (100, 150), 'price': 4.42, 'subcode': '030'},
{'bounds': (150, 200), 'price': 5.63, 'subcode': '040'},
{'bounds': (200, inf), 'price': 6.84, 'subcode': '050'}]}
A3 plot_product
Implement following function that takes a dictionary as output by previous extract_product and shows its price ranges.
pay attention to display title and axis labels as shown, using input data and not constants.
in case last range holds a
math.inf, show a>signif you don’t have a working
extract_product, just copy paste data from previous asserts.

[7]:
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
def plot_product(product):
raise Exception('TODO IMPLEMENT ME !')
product = extract_product('EPPAT-2018-new-compact.csv', 'A.02.40.0010', 'mm')
#product = extract_product('EPPAT-2018-new-compact.csv', 'A.02.40.0020', 'KW')
#product = extract_product('EPPAT-2018-new-compact.csv', 'B.02.10.0042', 'mm')
#product = extract_product('EPPAT-2018-new-compact.csv','B.30.10.0010', '%')
plot_product(product)


Part B
B1 Theory
Write the solution in separate ``theory.txt`` file
B1.1 complexity
Given a list L of n elements, please compute the asymptotic computational complexity of the following function, explaining your reasoning.
def my_fun(L):
n = len(L)
tmp = []
for i in range(int(n)):
tmp.insert(0,L[i]-L[int(n/3)])
return sum(tmp)
B1.2 describe
Briefly describe what a graph is and the two classic ways that can be used to represent it as a data structure.
B2 couple_sort
Open a text editor and edit file linked_list.py. Implement this method:
def couple_sort(self):
"""MODIFIES the linked list by considering couples of nodes at *even* indexes
and their successors: if a node data is lower than its successor data, swaps
the nodes *data*.
- ONLY swap *data*, DO NOT change node links.
- if linked list has odd size, simply ignore the exceeding node.
- MUST execute in O(n), where n is the size of the list
"""
Testing: python3 -m unittest linked_list_Test.CoupleSortTest
Example:
[8]:
from linked_list_sol import *
from linked_list_test import to_ll
[9]:
ll = to_ll([4,3,5,2,6,7,6,3,2,4,5,3,2])
[10]:
print(ll)
LinkedList: 4,3,5,2,6,7,6,3,2,4,5,3,2
[11]:
ll.couple_sort()
[12]:
print(ll)
LinkedList: 3,4,2,5,6,7,3,6,2,4,3,5,2
Notice it sorted each couple at even positions. This particular linked list has odd size (13 items), so last item 2 was not considered.
B3 schedule_rec
Suppose the nodes of a binary tree represent tasks (nodes data is the task label). Each task may have up to two subtasks, represented by its children. To be declared as completed, each task requires first the completion of all of its subtasks.
We want to create a schedule of tasks, so that to declare completed the task at the root of the tree, before all tasks below it must be completed, specifically first the tasks on the left side, and then the tasks on the right side. If you apply this reasoning recursively, you can obtain a schedule of tasks to be executed.
Open bin_tree.py and implement this method:
def schedule_rec(self):
""" RETURN a list of task labels in the order they will be completed.
- Implement it with recursive calls.
- MUST run in O(n) where n is the size of the tree
NOTE: with big trees a recursive solution would surely
exceed the call stack, but here we don't mind
"""
Testing: python3 -m unittest bin_tree_test.ScheduleRecTest
Example:
For this tree, it should return the schedule ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i']
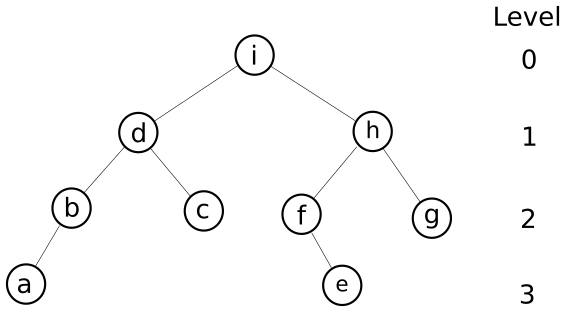
Here we show code execution with the same tree:
[13]:
from bin_tree_sol import *
from bin_tree_test import bt
[14]:
tasks = bt('i',
bt('d',
bt('b',
bt('a')),
bt('c')),
bt('h',
bt('f',
None,
bt('e')),
bt('g')))
[15]:
print(tasks)
i
├d
│├b
││├a
││└
│└c
└h
├f
│├
│└e
└g
[16]:
tasks.schedule_rec()
[16]:
['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i']