Exam - Mon 26, Aug 2019
Scientific Programming - Data Science @ University of Trento
Download exercises and solution
Introduction
Taking part to this exam erases any vote you had before
What to do
Download
sciprog-ds-2019-08-26-exam.zipand extract it on your desktop. Folder content should be like this:
sciprog-ds-2019-08-26-FIRSTNAME-LASTNAME-ID
exam-2019-08-26.ipynb
theory.txt
backpack.py
backpack_test.py
concert.py
concert_test.py
jupman.py
sciprog.py
Rename
sciprog-ds-2019-08-26-FIRSTNAME-LASTNAME-IDfolder: put your name, lastname an id number, likesciprog-ds-2019-08-26-john-doe-432432
From now on, you will be editing the files in that folder. At the end of the exam, that is what will be evaluated.
Edit the files following the instructions in this worksheet for each exercise. Every exercise should take max 25 mins. If it takes longer, leave it and try another exercise.
When done:
if you have unitn login: zip and send to examina.icts.unitn.it/studente
If you don’t have unitn login: tell instructors and we will download your work manually
Part A - University of Trento staff
NOTICE: this part of the exam was ported to softpython website
There you can find a more curated version (notice it may be longer than here)
Open Jupyter and start editing this notebook exam-2019-08-26.ipynb
You will work on the dataset of University of Trento staff, modified so not to contain names or surnames.
Data provider: University of Trento
A function load_data is given to load the dataset (you don’t need to implement it):
[1]:
import json
def load_data():
with open('data/2019-06-30-persone-en-stripped.json', encoding='utf-8') as json_file:
data = json.load(json_file)
return data
unitn = load_data()
IMPORTANT: look at the dataset !
Here we show only first 2 rows, but to get a clear picture of the dataset you should explore it further.
The dataset contains a list of employees, each of whom may have one or more positions, in one or more university units. Each unit is identified by a code like STO0000435:
[2]:
unitn[:2]
[2]:
[{'givenName': 'NAME-1',
'phone': ['0461 283752'],
'identifier': 'eb9139509dc40d199b6864399b7e805c',
'familyName': 'SURNAME-1',
'positions': [{'unitIdentifier': 'STO0008929',
'role': 'Staff',
'unitName': 'Student Support Service: Economics, Law and International Studies'}]},
{'givenName': 'NAME-2',
'phone': ['0461 281521'],
'identifier': 'b6292ffe77167b31e856d2984544e45b',
'familyName': 'SURNAME-2',
'positions': [{'unitIdentifier': 'STO0000435',
'role': 'Associate professor',
'unitName': 'Doctoral programme – Physics'},
{'unitIdentifier': 'STO0000435',
'role': 'Deputy coordinator',
'unitName': 'Doctoral programme – Physics'},
{'unitIdentifier': 'STO0008627',
'role': 'Associate professor',
'unitName': 'Department of Physics'}]}]
Department names can be very long, so when you need to display them you can use the function this abbreviate.
NOTE: function is already fully implemented, do not modify it.
[3]:
def abbreviate(unitName):
abbreviations = {
"Department of Psychology and Cognitive Science": "COGSCI",
"Center for Mind/Brain Sciences - CIMeC":"CIMeC",
"Department of Civil, Environmental and Mechanical Engineering":"DICAM",
"Centre Agriculture Food Environment - C3A":"C3A",
"School of International Studies - SIS":"SIS",
"Department of Sociology and social research": "Sociology",
"Faculty of Law": "Law",
"Department of Economics and Management": "Economics",
"Department of Information Engineering and Computer Science":"DISI",
"Department of Cellular, Computational and Integrative Biology - CIBIO":"CIBIO",
"Department of Industrial Engineering":"DII"
}
if unitName in abbreviations:
return abbreviations[unitName]
else:
return unitName.replace("Department of ", "")
Example:
[4]:
abbreviate("Department of Information Engineering and Computer Science")
[4]:
'DISI'
A1 calc_uid_to_abbr
✪ It will be useful having a map from department ids to their abbreviations, if they are actually present, otherwise to their original name. To implement this, you can use the previously defined function abbreviate.
{
.
.
'STO0008629': 'DISI',
'STO0008630': 'Sociology',
'STO0008631': 'COGSCI',
.
.
'STO0012897': 'Institutional Relations and Strategic Documents',
.
.
}
[5]:
def calc_uid_to_abbr(db):
raise Exception('TODO IMPLEMENT ME !')
#calc_uid_to_abbr(unitn)
print(calc_uid_to_abbr(unitn)['STO0008629'])
print(calc_uid_to_abbr(unitn)['STO0012897'])
DISI
Institutional Relations and Strategic Documents
A2.1 calc_prof_roles
✪✪ For each department, we want to see how many professor roles are covered, sorting them from greatest to lowest. In returned list we will only put the 10 department with most roles.
NOTE 1: we are interested in roles covered. Don’t care if actual people might be less (one person can cover more professor roles within the same unit)
NOTE 2: there are several professor roles. Please avoid listing all roles in the code (“Senior Professor’, “Visiting Professor”, ….), and prefer using some smarter way to match them.
[6]:
def calc_prof_roles(db):
raise Exception('TODO IMPLEMENT ME !')
#calc_prof_roles(unitn)
[7]:
# EXPECTED RESULT
calc_prof_roles(unitn)
[7]:
[('Humanities', 92),
('DICAM', 85),
('Law', 84),
('Economics', 83),
('Sociology', 66),
('COGSCI', 61),
('Physics', 60),
('DISI', 55),
('DII', 49),
('Mathematics', 47)]
A2.2 plot_profs
✪ Write a funciton to plot a bar chart of data calculated above
Show solution[8]:
%matplotlib inline
import matplotlib.pyplot as plt
def plot_profs(db):
raise Exception('TODO IMPLEMENT ME !')
#plot_profs(unitn)
[9]:
# EXPECTED RESULT
plot_profs(unitn)
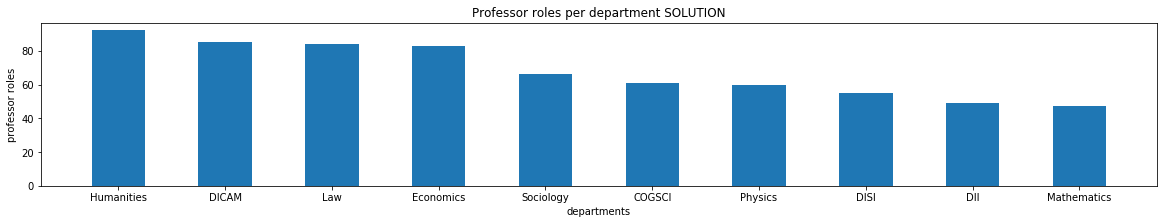
A3.1 calc_roles
✪✪ We want to calculate how many roles are covered for each department.
You will group roles by these macro groups (some already exist, some are new):
Professor : “Senior Professor’, “Visiting Professor”, …
Research : “Senior researcher”, “Research collaborator”, …
Teaching : “Teaching assistant”, “Teaching fellow”, …
Guest : “Guest”, …
and discard all the others (there are many, like “Rector”, “Head”, etc ..)
NOTE: Please avoid listing all roles in the code (“Senior researcher”, “Research collaborator”, …), and prefer using some smarter way to match them.
Show solution[10]:
def calc_roles(db):
raise Exception('TODO IMPLEMENT ME !')
#print(calc_roles(unitn)['STO0000001'])
#print(calc_roles(unitn)['STO0000006'])
#print(calc_roles(unitn)['STO0000012'])
#print(calc_roles(unitn)['STO0008629'])
EXPECTED RESULT - Showing just first ones …
>>> calc_roles(unitn)
{
'STO0000001': {'Teaching': 9, 'Research': 3, 'Professor': 12},
'STO0000006': {'Professor': 1},
'STO0000012': {'Guest': 3},
'STO0008629': {'Teaching': 94, 'Research': 71, 'Professor': 55, 'Guest': 38}
.
.
.
}
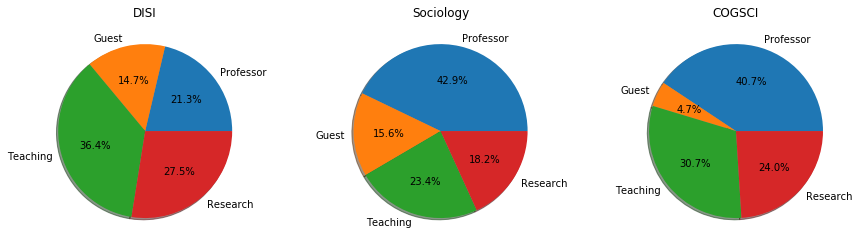
A3.2 plot_roles
✪✪ Implement a function plot_roles that given, the abbreviations (or long names) of some departments, plots pie charts of their grouped role distribution, all in one row.
NOTE 1: different plots MUST show equal groups with equal colors
NOTE 2: always show all the 4 macro groups defined before, even if they have zero frequency
For on example on how to plot the pie charts, see this
For on example on plotting side by side, see this
[11]:
%matplotlib inline
import matplotlib.pyplot as plt
def plot_roles(db, abbrs):
raise Exception('TODO IMPLEMENT ME !')
#plot_roles(unitn, ['DISI','Sociology', 'COGSCI'])
[12]:
# EXPECTED RESULT
plot_roles(unitn, ['DISI','Sociology', 'COGSCI'])
A4.2 plot_shared
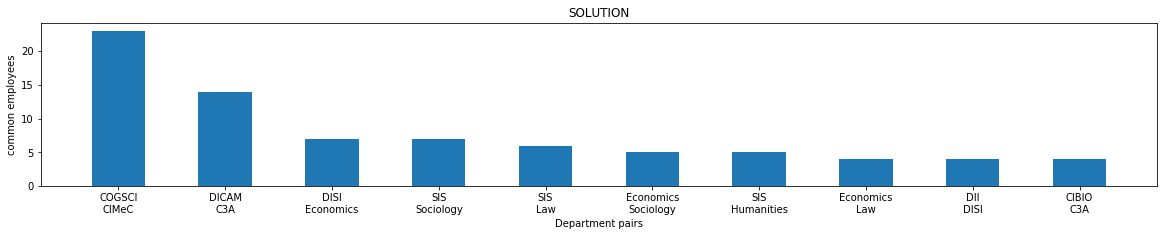
✪ Plot the above in a bar chart, where on the x axis there are the department pairs and on the y the number of people in common.
Show solution[15]:
import matplotlib.pyplot as plt
%matplotlib inline
def plot_shared(db):
raise Exception('TODO IMPLEMENT ME !')
#plot_shared(unitn)
[16]:
# EXPECTED RESULT
plot_shared(unitn)
Part B
B1 Theory
Write the solution in separate ``theory.txt`` file
Let M be a square matrix - a list containing n lists, each of them of size n. Return the computational complexity of function fun() with respect to n:
def fun(M):
for row in M:
for element in row:
print(sum([x for x in row if x != element]))
B2 Backpack
Open a text editor and edit file backpack_sol.py
We can model a backpack as stack of elements, each being a tuple with a name and a weight.
A sensible strategy to fill a backpack is to place heaviest elements to the bottom, so our backback will allow pushing an element only if that element weight is equal or lesser than current topmost element weight.
The backpack has also a maximum weight: you can put any number of items you want, as long as its maximum weight is not exceeded.
Example
[17]:
from backpack_sol import *
bp = Backpack(30) # max_weight = 30
bp.push('a',10) # item 'a' with weight 10
DEBUG: Pushing (a,10)
[18]:
print(bp)
Backpack: weight=10 max_weight=30
elements=[('a', 10)]
[19]:
bp.push('b',8)
DEBUG: Pushing (b,8)
[20]:
print(bp)
Backpack: weight=18 max_weight=30
elements=[('a', 10), ('b', 8)]
>>> bp.push('c', 11)
DEBUG: Pushing (c,11)
ValueError: ('Pushing weight greater than top element weight! %s > %s', (11, 8))
[21]:
bp.push('c', 7)
DEBUG: Pushing (c,7)
[22]:
print(bp)
Backpack: weight=25 max_weight=30
elements=[('a', 10), ('b', 8), ('c', 7)]
>>> bp.push('d', 6)
DEBUG: Pushing (d,6)
ValueError: Can't exceed max_weight ! (31 > 30)
B2.1 class
✪✪ Implement methods in the class Backpack, in the order they are shown. If you want, you can add debug prints by calling the debug function
IMPORTANT: the data structure should provide the total current weight in O(1), so make sure to add and update an appropriate field to meet this constraint.
Testing: python3 -m unittest backpack_test.BackpackTest
B2.2 remove
✪✪ Implement function remove:
# NOTE: this function is implemented *outside* the class !
def remove(backpack, el):
"""
Remove topmost occurrence of el found in the backpack,
and RETURN it (as a tuple name, weight)
- if el is not found, raises ValueError
- DO *NOT* ACCESS DIRECTLY FIELDS OF BACKPACK !!!
Instead, just call methods of the class!
- MUST perform in O(n), where n is the backpack size
- HINT: To remove el, you need to call Backpack.pop() until
the top element is what you are looking for. You need
to save somewhere the popped items except the one to
remove, and then push them back again.
"""
Testing: python3 -m unittest backpack_test.RemoveTest
Example:
[23]:
bp = Backpack(50)
bp.push('a',9)
bp.push('b',8)
bp.push('c',8)
bp.push('b',8)
bp.push('d',7)
bp.push('e',5)
bp.push('f',2)
DEBUG: Pushing (a,9)
DEBUG: Pushing (b,8)
DEBUG: Pushing (c,8)
DEBUG: Pushing (b,8)
DEBUG: Pushing (d,7)
DEBUG: Pushing (e,5)
DEBUG: Pushing (f,2)
[24]:
print(bp)
Backpack: weight=47 max_weight=50
elements=[('a', 9), ('b', 8), ('c', 8), ('b', 8), ('d', 7), ('e', 5), ('f', 2)]
[25]:
remove(bp, 'b')
DEBUG: Popping ('f', 2)
DEBUG: Popping ('e', 5)
DEBUG: Popping ('d', 7)
DEBUG: Popping ('b', 8)
DEBUG: Pushing (d,7)
DEBUG: Pushing (e,5)
DEBUG: Pushing (f,2)
[25]:
('b', 8)
[26]:
print(bp)
Backpack: weight=39 max_weight=50
elements=[('a', 9), ('b', 8), ('c', 8), ('d', 7), ('e', 5), ('f', 2)]
B.3 Concert
Start editing file concert.py.
When there are events with lots of potential visitors such as concerts, to speed up check-in there are at least two queues: one for cash where tickets are sold, and one for the actual entrance at the event.
Each visitor may or may not have a ticket. Also, since people usually attend in groups (coupls, families, and so on), in the queue lines each group tends to move as a whole.
In Python, we will model a Person as a class you can create like this:
[27]:
from concert_sol import *
[28]:
Person('a', 'x', False)
[28]:
Person(a,x,False)
a is the name, 'x' is the group, and False indicates the person doesn’t have ticket
To model the two queues, in Concert class we have these fields and methods:
class Concert:
def __init__(self):
self._cash = deque()
self._entrance = deque()
def enqc(self, person):
""" Enqueues at the cash from the right """
self._cash.append(person)
def enqe(self, person):
""" Enqueues at the entrance from the right """
self._entrance.append(person)
B3.1 dequeue
✪✪✪ Implement dequeue. If you want, you can add debug prints by calling the debug function.
def dequeue(self):
""" RETURN the names of people admitted to concert
Dequeuing for the whole queue system is done in groups, that is,
with a _single_ call to dequeue, these steps happen, in order:
1. entrance queue: all people belonging to the same group at
the front of entrance queue who have the ticket exit the queue
and are admitted to concert. People in the group without the
ticket are sent to cash.
2. cash queue: all people belonging to the same group at the front
of cash queue are given a ticket, and are queued at the entrance queue
"""
Testing: python3 -m unittest concert_test.DequeueTest
Example:
[29]:
con = Concert()
con.enqc(Person('a','x',False)) # a,b,c belong to same group x
con.enqc(Person('b','x',False))
con.enqc(Person('c','x',False))
con.enqc(Person('d','y',False)) # d belongs to group y
con.enqc(Person('e','z',False)) # e,f belongs to group z
con.enqc(Person('f','z',False))
con.enqc(Person('g','w',False)) # g belongs to group w
[30]:
con
[30]:
Concert:
cash: deque([Person(a,x,False),
Person(b,x,False),
Person(c,x,False),
Person(d,y,False),
Person(e,z,False),
Person(f,z,False),
Person(g,w,False)])
entrance: deque([])
First time we dequeue, entrance queue is empty so no one enters concert, while at the cash queue people in group x are given a ticket and enqueued at the entrance queue
NOTE: The messages on the console are just debug print, the function dequeue only return name sof people admitted to concert
[31]:
con.dequeue()
DEBUG: DEQUEUING ..
DEBUG: giving ticket to a (group x)
DEBUG: giving ticket to b (group x)
DEBUG: giving ticket to c (group x)
DEBUG: Concert:
cash: deque([Person(d,y,False),
Person(e,z,False),
Person(f,z,False),
Person(g,w,False)])
entrance: deque([Person(a,x,True),
Person(b,x,True),
Person(c,x,True)])
[31]:
[]
[32]:
con.dequeue()
DEBUG: DEQUEUING ..
DEBUG: a (group x) admitted to concert
DEBUG: b (group x) admitted to concert
DEBUG: c (group x) admitted to concert
DEBUG: giving ticket to d (group y)
DEBUG: Concert:
cash: deque([Person(e,z,False),
Person(f,z,False),
Person(g,w,False)])
entrance: deque([Person(d,y,True)])
[32]:
['a', 'b', 'c']
[33]:
con.dequeue()
DEBUG: DEQUEUING ..
DEBUG: d (group y) admitted to concert
DEBUG: giving ticket to e (group z)
DEBUG: giving ticket to f (group z)
DEBUG: Concert:
cash: deque([Person(g,w,False)])
entrance: deque([Person(e,z,True),
Person(f,z,True)])
[33]:
['d']
[34]:
con.dequeue()
DEBUG: DEQUEUING ..
DEBUG: e (group z) admitted to concert
DEBUG: f (group z) admitted to concert
DEBUG: giving ticket to g (group w)
DEBUG: Concert:
cash: deque([])
entrance: deque([Person(g,w,True)])
[34]:
['e', 'f']
[35]:
con.dequeue()
DEBUG: DEQUEUING ..
DEBUG: g (group w) admitted to concert
DEBUG: Concert:
cash: deque([])
entrance: deque([])
[35]:
['g']
[36]:
# calling dequeue on empty lines gives empty list:
con.dequeue()
DEBUG: DEQUEUING ..
DEBUG: Concert:
cash: deque([])
entrance: deque([])
[36]:
[]
Special dequeue case: broken group
In the special case when there is a group at the entrance with one or more members without a ticket, it is assumed that the group gets broken, so whoever has the ticket enters and the others get enqueued at the cash.
[37]:
con = Concert()
con.enqe(Person('a','x',True))
con.enqe(Person('b','x',False))
con.enqe(Person('c','x',True))
con.enqc(Person('f','y',False))
con
[37]:
Concert:
cash: deque([Person(f,y,False)])
entrance: deque([Person(a,x,True),
Person(b,x,False),
Person(c,x,True)])
[38]:
con.dequeue()
DEBUG: DEQUEUING ..
DEBUG: a (group x) admitted to concert
DEBUG: b (group x) has no ticket! Sending to cash
DEBUG: c (group x) admitted to concert
DEBUG: giving ticket to f (group y)
DEBUG: Concert:
cash: deque([Person(b,x,False)])
entrance: deque([Person(f,y,True)])
[38]:
['a', 'c']
[39]:
con.dequeue()
DEBUG: DEQUEUING ..
DEBUG: f (group y) admitted to concert
DEBUG: giving ticket to b (group x)
DEBUG: Concert:
cash: deque([])
entrance: deque([Person(b,x,True)])
[39]:
['f']
[40]:
con.dequeue()
DEBUG: DEQUEUING ..
DEBUG: b (group x) admitted to concert
DEBUG: Concert:
cash: deque([])
entrance: deque([])
[40]:
['b']
[41]:
con
[41]:
Concert:
cash: deque([])
entrance: deque([])
[42]:
import jupman;
import backpack_sol
import backpack_test
backpack_sol.DEBUG = False
jupman.run(backpack_test)
import concert_sol
import concert_test
concert_sol.DEBUG = False
jupman.run(concert_test)
..................
----------------------------------------------------------------------
Ran 18 tests in 0.010s
OK
.......
----------------------------------------------------------------------
Ran 7 tests in 0.004s
OK
[ ]: