Midterm Sim - Tue 13, Nov 2018
Scientific Programming - Data Science Master @ University of Trento
Download exercises and solution
Introduction
This simulation gives you NO credit whatsoever, it’s just an example. If you do everything wrong, you lose nothing. If you do everything correct, you gain nothing.
What to do
Download
sciprog-ds-2018-11-13-exam.zipand extract it on your desktop. Folder content should be like this:
sciprog-ds-2018-11-13-FIRSTNAME-LASTNAME-ID
A1.ipynb
A2.ipynb
B1.py
B1_test.py
B2.py
B2_test.py
jupman.py
sciprog.py
Rename
sciprog-ds-2018-11-13-FIRSTNAME-LASTNAME-IDfolder: put your name, lastname an id number, likesciprog-ds-2018-11-12-john-doe-432432
From now on, you will be editing the files in that folder. At the end of the exam, that is what will be evaluated.
Edit the files following the instructions in this worksheet for each exercise. Every exercise should take max 25 mins. If it takes longer, leave it and try another exercise.
1. matrices
1.1 fill
Difficulty: ✪✪
Show solution[2]:
def fill(lst1, lst2):
""" Takes a list lst1 of n elements and a list lst2 of m elements, and MODIFIES lst2
by copying all lst1 elements in the first n positions of lst2
If n > m, raises a ValueError
"""
raise Exception('TODO IMPLEMENT ME !')
try:
fill(['a','b'], [None])
raise Exception("TEST FAILED: Should have failed before with a ValueError!")
except ValueError:
"Test passed"
try:
fill(['a','b','c'], [None,None])
raise Exception("TEST FAILED: Should have failed before with a ValueError!")
except ValueError:
"Test passed"
L1 = []
R1 = []
fill(L1, R1)
assert L1 == []
assert R1 == []
L = []
R = ['x']
fill(L, R)
assert L == []
assert R == ['x']
L = ['a']
R = ['x']
fill(L, R)
assert L == ['a']
assert R == ['a']
L = ['a']
R = ['x','y']
fill(L, R)
assert L == ['a']
assert R == ['a','y']
L = ['a','b']
R = ['x','y']
fill(L, R)
assert L == ['a','b']
assert R == ['a','b']
L = ['a','b']
R = ['x','y','z',]
fill(L, R)
assert L == ['a','b']
assert R == ['a','b','z']
L = ['a']
R = ['x','y','z',]
fill(L, R)
assert L == ['a']
assert R == ['a','y','z']
1.2 lab
✪✪✪ If you’re a teacher that often see new students, you have this problem: if two students who are friends sit side by side they can start chatting way too much. To keep them quiet, you want to somehow randomize student displacement by following this algorithm:
first sort the students alphabetically
then sorted students progressively sit at the available chairs one by one, first filling the first row, then the second, till the end.
Now implement the algorithm:
Show solution[3]:
def lab(students, chairs):
"""
INPUT:
- students: a list of strings of length <= n*m
- chairs: an nxm matrix as list of lists filled with None values (empty chairs)
OUTPUT: MODIFIES BOTH students and chairs inputs, without returning anything
If students are more than available chairs, raises ValueError
Example:
ss = ['b', 'd', 'e', 'g', 'c', 'a', 'h', 'f' ]
mat = [
[None, None, None],
[None, None, None],
[None, None, None],
[None, None, None]
]
lab(ss, mat)
# after execution, mat should result changed to this:
assert mat == [
['a', 'b', 'c'],
['d', 'e', 'f'],
['g', 'h', None],
[None, None, None],
]
# after execution, input ss should now be ordered:
assert ss == ['a','b','c','d','e','f','g','f']
For more examples, see tests
"""
raise Exception('TODO IMPLEMENT ME !')
try:
lab(['a','b'], [[None]])
raise Exception("TEST FAILED: Should have failed before with a ValueError!")
except ValueError:
"Test passed"
try:
lab(['a','b','c'], [[None,None]])
raise Exception("TEST FAILED: Should have failed before with a ValueError!")
except ValueError:
"Test passed"
m0 = [
[None]
]
r0 = lab([],m0)
assert m0 == [
[None]
]
assert r0 == None # function is not meant to return anything (so returns None by default)
m1 = [
[None]
]
r1 = lab(['a'], m1)
assert m1 == [
['a']
]
assert r1 == None # function is not meant to return anything (so returns None by default)
m2 = [
[None, None]
]
lab(['a'], m2) # 1 student 2 chairs in one row
assert m2 == [
['a', None]
]
m3 = [
[None],
[None],
]
lab(['a'], m3) # 1 student 2 chairs in one column
assert m3 == [
['a'],
[None]
]
ss4 = ['b', 'a']
m4 = [
[None, None]
]
lab(ss4, m4) # 2 students 2 chairs in one row
assert m4 == [
['a','b']
]
assert ss4 == ['a', 'b'] # also modified input list as required by function text
m5 = [
[None, None],
[None, None]
]
lab(['b', 'c', 'a'], m5) # 3 students 2x2 chairs
assert m5 == [
['a','b'],
['c', None]
]
m6 = [
[None, None],
[None, None]
]
lab(['b', 'd', 'c', 'a'], m6) # 4 students 2x2 chairs
assert m6 == [
['a','b'],
['c','d']
]
m7 = [
[None, None, None],
[None, None, None]
]
lab(['b', 'd', 'e', 'c', 'a'], m7) # 5 students 3x2 chairs
assert m7 == [
['a','b','c'],
['d','e',None]
]
ss8 = ['b', 'd', 'e', 'g', 'c', 'a', 'h', 'f' ]
m8 = [
[None, None, None],
[None, None, None],
[None, None, None],
[None, None, None]
]
lab(ss8, m8) # 8 students 3x4 chairs
assert m8 == [
['a', 'b', 'c'],
['d', 'e', 'f'],
['g', 'h', None],
[None, None, None],
]
assert ss8 == ['a','b','c','d','e','f','g','h']
2. phones
NOTICE: this part of the exam was ported to softpython website
There you can find a more curated version (notice it may be longer than here)
A radio station used to gather calls by recording just the name of the caller and the phone number as seen on the phone display. For marketing purposes, the station owner wants now to better understand the places from where listeners where calling. He then hires you as Algorithmic Market Strategist and asks you to show statistics about the provinces of the calling sites. There is a problem, though. Numbers where written down by hand and sometimes they are not uniform, so it would be better to find a canonical representation.
NOTE: Phone prefixes can be a very tricky subject, if you are ever to deal with them seriously please use proper phone number parsing libraries and do read Falsehoods Programmers Believe About Phone Numbers
2.1 canonical
✪ We first want to canonicalize a phone number as a string.
For us, a canonical phone number:
contains no spaces
contains no international prefix, so no
+39nor0039: we assume all calls where placed from Italy (even if they have international prefix)
For example, all of these are canonicalized to “0461123456”:
+39 0461 123456
+390461123456
0039 0461 123456
00390461123456
These are canonicalized as the following:
328 123 4567 -> 3281234567
0039 328 123 4567 -> 3281234567
0039 3771 1234567 -> 37711234567
REMEMBER: strings are immutable !!!!!
Show solution[4]:
def canonical(phone):
""" RETURN the canonical version of phone as a string. See above for an explanation.
"""
raise Exception('TODO IMPLEMENT ME !')
assert canonical('+39 0461 123456') == '0461123456'
assert canonical('+390461123456') == '0461123456'
assert canonical('0039 0461 123456') == '0461123456'
assert canonical('00390461123456') == '0461123456'
assert canonical('003902123456') == '02123456'
assert canonical('003902120039') == '02120039'
assert canonical('0039021239') == '021239'
2.2 prefix
✪✪ We now want to extract the province prefix - the ones we consider as valid are in province_prefixes list.
Note some numbers are from mobile operators and you can distinguish them by prefixes like 328 - the ones we consider are in an mobile_prefixes list.
[5]:
province_prefixes = ['0461', '02', '011']
mobile_prefixes = ['330', '340', '328', '390', '3771']
def prefix(phone):
""" RETURN the prefix of the phone as a string. Remeber first to make it canonical !!
If phone is mobile, RETURN string 'mobile'. If it is not a phone nor a mobile, RETURN
the string 'unrecognized'
To determine if the phone is mobile or from province, use above province_prefixes and mobile_prefixes lists.
DO USE THE ALREADY DEFINED FUCTION canonical(phone)
"""
raise Exception('TODO IMPLEMENT ME !')
assert prefix('0461123') == '0461'
assert prefix('+39 0461 4321') == '0461'
assert prefix('0039011 432434') == '011'
assert prefix('328 432434') == 'mobile'
assert prefix('+39340 432434') == 'mobile'
assert prefix('00666011 432434') == 'unrecognized'
assert prefix('12345') == 'unrecognized'
assert prefix('+39 123 12345') == 'unrecognized'
2.3 hist
Difficulty: ✪✪✪
Show solution[6]:
province_prefixes = ['0461', '02', '011']
mobile_prefixes = ['330', '340', '328', '390', '3771']
def hist(phones):
""" Given a list of non-canonical phones, RETURN a dictionary where the keys are the prefixes of the canonical phones
and the values are the frequencies of the prefixes (keys may also be `unrecognized' or `mobile`)
NOTE: Numbers corresponding to the same phone (so which have the same canonical representation)
must be counted ONLY ONCE!
DO USE THE ALREADY DEFINED FUCTIONS canonical(phone) AND prefix(phone)
"""
raise Exception('TODO IMPLEMENT ME !')
assert hist(['0461123']) == {'0461':1}
assert hist(['123']) == {'unrecognized':1}
assert hist(['328 123']) == {'mobile':1}
assert hist(['0461123','+390461123']) == {'0461':1} # same canonicals, should be counted only once
assert hist(['0461123', '+39 0461 4321']) == {'0461':2}
assert hist(['0461123', '+39 0461 4321', '0039011 432434']) == {'0461':2, '011':1}
assert hist(['+39 02 423', '0461123', '02 426', '+39 0461 4321', '0039328 1234567', '02 423', '02 424']) == {'0461':2, 'mobile':1, '02':3}
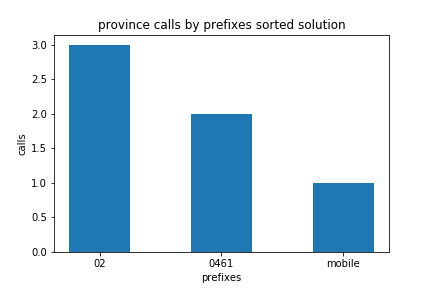
2.4 display calls by prefixes
✪✪ Using matplotlib, display a bar plot of the frequency of calls by prefixes (including mobile and unrecognized), sorting them in reverse order so you first see the province with the higher number of calls. Also, save the plot on disk with plt.savefig('prefixes-count.png') (call it before plt.show())
If you’re in trouble you can find plenty of examples in the visualization chapter
You should obtain something like this:
[7]:
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
province_prefixes = ['0461', '02', '011']
mobile_prefixes = ['330', '340', '328', '390', '3771']
phones = ['+39 02 423', '0461123', '02 426', '+39 0461 4321', '0039328 1234567', '02 423', '02 424']
# write here
[8]: